My corpus is comprised of data collected and stored as a part of the Child Languages Data Exchange System database a part of the TalkBank system of collected speech transcriptions. The database is maintained by Professor Brian MacWhinney at Carnegie Mellon University since the 1990s, and has become one of, if not the largest single collection of spoken child utterances available. The data within the system dates as far back as the 1960s and is continually updated with additional transcriptions from more recent studies. This corpus was then analyzed using CHILDES’s open-source analysis software, CLAN, in order to divide the large pool of data into smaller subsets organized by Roger Brown’s Stages for Syntactical and Morphological Development. This model divides the different stages of a child’s syntactical speech progression into 5 stages representing the most basic child speech to more syntactically advanced sentence structures. One interesting thing to note here is that the data itself is not actually organized by the individual speaker’s age whatsoever, but merely by the various stages I have previously outlined. That being said, there are some general age mappings for Brown’s stages that happen to appear in the data present. For instance, simpler sentences are more likely spoken by younger children while more complex sentences are more likely spoken by older ones. These divisions have proven very interesting in visualization analysis for my accumulated corpora.
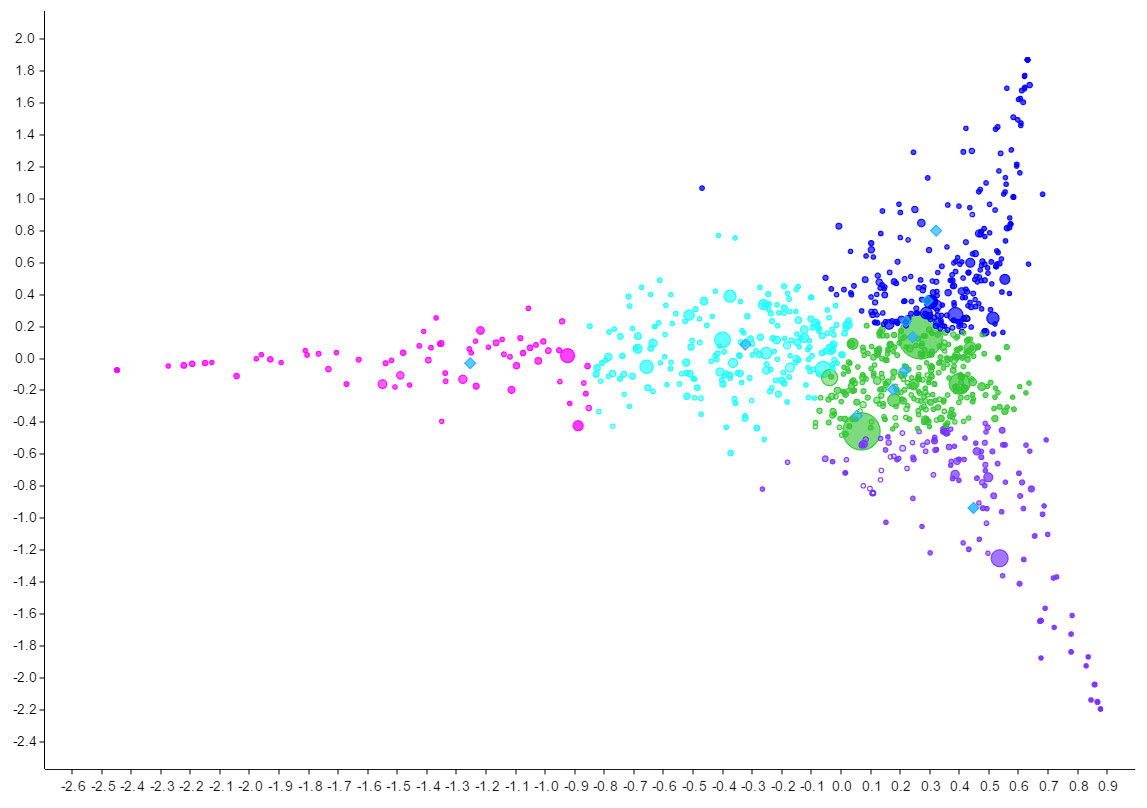 The above images display a scatter plot of my corpus’ word data created using the Voyant platform. The above visualization breaks down the 1000 most frequently used words from my corpus and then break them into clusters by relative usage (displayed via different colors). These different nodes are then placed on a plot in relation to each other based off of their relative use and connections within the text. This visualization is novel in its ability to display the interconnected nature of early speech sentence structure. All spoken utterances are cleanly related to their counterparts, branching off into three separate off-shoots from the main base of language. What surprises me the most about this visualization is how clean this relation is, and how geometric it is as well.
The above images display a scatter plot of my corpus’ word data created using the Voyant platform. The above visualization breaks down the 1000 most frequently used words from my corpus and then break them into clusters by relative usage (displayed via different colors). These different nodes are then placed on a plot in relation to each other based off of their relative use and connections within the text. This visualization is novel in its ability to display the interconnected nature of early speech sentence structure. All spoken utterances are cleanly related to their counterparts, branching off into three separate off-shoots from the main base of language. What surprises me the most about this visualization is how clean this relation is, and how geometric it is as well.
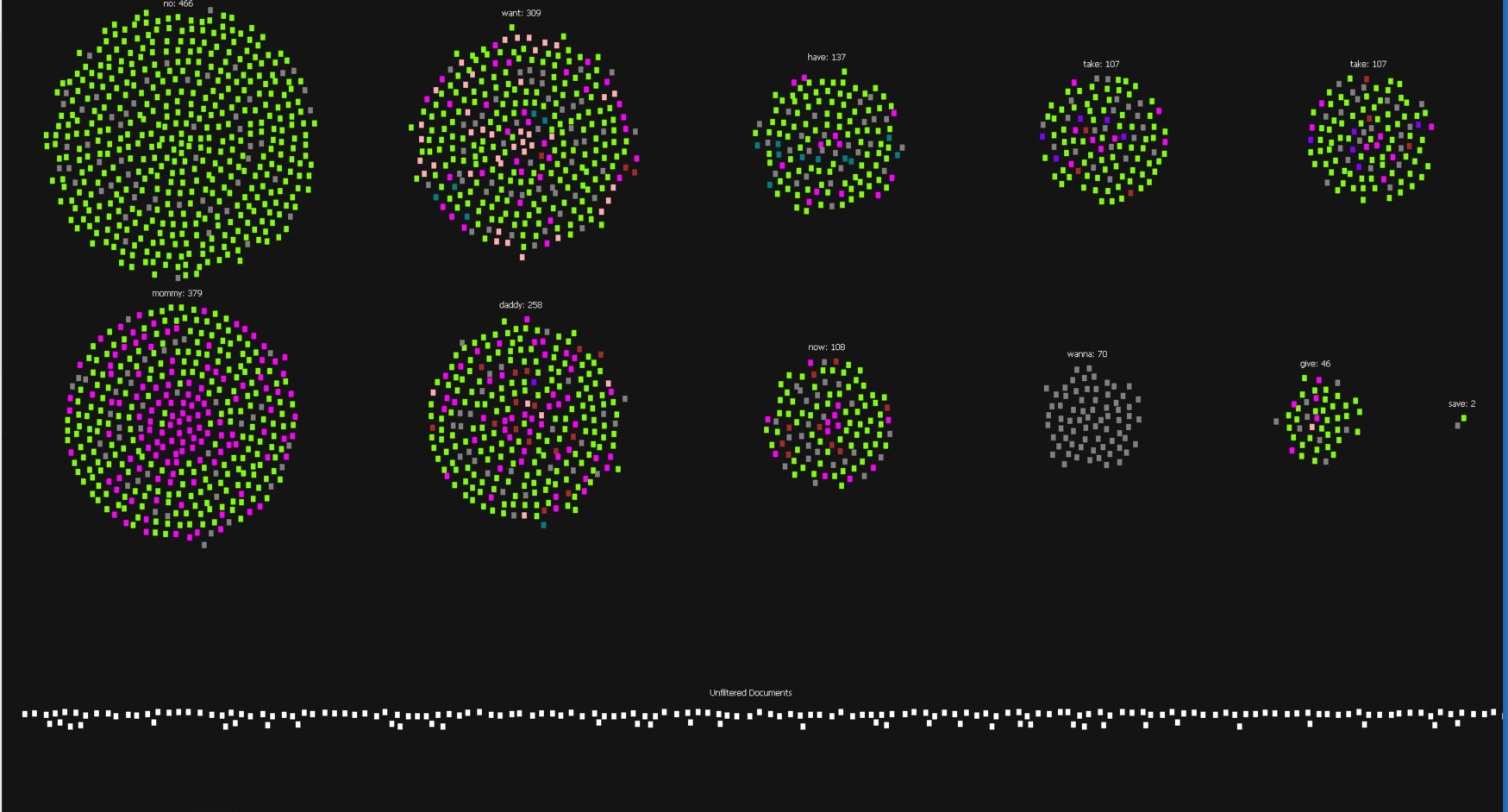

The above visualization was created using the Jigsaw platform. The main take-away that this visualization presents immediately is the direct relation between words of urgency and between utterances of “mommy” or “daddy”. While this may appear obvious from a distance, seeing these rather dissimilar words that merely share the trait of urgency all having higher frequency of relations to utterances for parents is very interesting. As well, the sheer number of utterances of “mommy” compared to other types of names or actions is quite interesting to behold.
The obvious difference between the Voyant and Jigsaw platforms is in the way each handles the data that it processes. Voyant is more interested in word frequencies and relative originality of individual terms while Jigsaw is more focused on putting context into the words that it is given by dividing them into entities for analysis. Because of the nature of this context-based approach, Jigsaw isn’t very useful for large-scale text files that haven’t been properly parsed yet. For instance, Jigsaw is quite good at reading books or formal reports because of the way in which subjects are formatted and displayed within the texts. But for my corpora, I have a very large number of spoken utterances by children which aren’t always as syntactically literate as these. Because of this, I was tasked with defining my own set of entities based off of the components of my text that I wished to explore. Some examples of entities that I used are different pronoun forms, family members, and words of urgency. From there, I was able to make connections between these various groups using Jigsaw’s extensive document analysis and clustering tools. Voyant doesn’t allow you this much specific control. But, where Jigsaw succeeds in entity and core analysis, Voyant makes up for in large text analysis. Using Voyant I was able to make over-arching analytical conclusions about word usage which isn’t as clear when using Jigsaw. Both platforms are quite extensive in their offerings, as long as the data you are working with is tailored to what each platform provides.
The creation of this corpus, as well as the process of analyzing it with these two similar yet disparate platforms has yielded an interesting insight into what Clement was trying to get at in her piece on Analysis and Visualizations. On one hand, these images in front of me are displaying concrete information which was gathered from valid sources for analysis. Yet, all of this visualization is taking place in a completely virtual environment. None of it is physical, unless it were to be printed out or written down manually. This incongruity is interesting in the fact that it gives the researcher a reminder of the constraints of a virtual analysis process, while also appreciating that without the humanistic element to the analysis, no real conclusions could be drawn. We are simultaneously working as humanists and computer scientists in these moments, and are capable of making connections that neither could do alone.
Leave a Reply